Weekly Reports
Semester 1
Conducted client meetings and preliminary research, but remained in a holding pattern waiting for
NDAs, hardware, and codebase access.
Onboarded into specialized project areas with Joseph studying Kria board specifications and memory
optimization, Tyler meeting with the ISU team and familiarizing himself with ONNX files, Conner
establishing communications with Oregon State and setting up Dev environments, and Aidan focusing on
the multi-threading implementation in the C++ codebase for image processing optimization.
Deepened our understanding of the codebase through comments, diagrams, and meetings with former team
members. Joseph researched Kria Board components for our assignment, created a slide deck, and
explored Xilinx Vitis, while Tyler met with Mason Inman and our client to discuss algorithm
environment setup and quantization needs. Conner built the Petalinux OS, wrote nix derivations for
multithreaded builds, created a data version control presentation, and gave a lightning talk on
U-Net architecture. Aidan connected with last semester's multithreaded programming developer,
reviewed previous presentations, and tested matrix implementations to better understand the
algorithm.
Transition from theoretical learning to hands-on experimentation. Joseph finalized component
selections for the project and studied data flow through the Kria Board. Tyler successfully
configured the Vitis-AI docker container and trained the existing model to demonstrate proper
environment setup to the client. Conner created a test application that split a PyTorch segmentation
model into separate encoder and decoder ONNX models for initial multicore processing experiments
(later analysis would reveal DPU limitations with this approach). Aidan continued collaboration with
the previous codebase owner while developing matrix equations for the multithreaded pipeline and
becoming familiar with the `cv::mat` class.
Making progress on software installations for properly running and visualizing the Kria board
operations. Tyler researched optimization techniques specifically for U-Nets and CNNs on embedded
systems. Conner fixed and improved the broken Docker development environment, making it more
configurable, testing it across multiple platforms with GitHub Actions, and submitted PRs for both
this fix and a slide deck presenting his data version control system proposal. Aidan formulated test
equations for the multi-threading system and consulted with the previous codebase owner to validate
his approach.
Further optimizing the Kria board while advancing research on model splitting to improve
computational efficiency. Joseph studied memory flow optimization for the Kria board. Tyler
continued researching computational complexity and began creating a slide deck to propose a
strategic model split. Aidan continued research on the `cv::mat` class, re-theorized the algorithm
input structure, and held one-on-one meetings with both the client and past developers. Planning
initializing benchmark testing of the old code, presenting the proposed model division to the
client, testing the custom Petalinux images with previous code, and developing a test input in
`cv::mat` format to identify flaws in the current system.
Benchmarking and technical documentation while preparing for future implementation. Joseph worked
with Conner to benchmark memory performance on the Kria board, specifically measuring data transfer
rates between L1/L2 caches and RAM while exploring optimization strategies producing an 36-page
memory benchmark documentation with approximately 12 graphs, complete with code examples (using
Python for plotting, C for benchmarking, and Markdown for documentation). Tyler completed his
computational complexity analysis and prepared a presentation for both the team and client to
propose his algorithm division approach. Aidan reached out to a professor for expert consultation on
optimal data structures for our implementation while continuing his theoretical work on designing
inputs for thread testing and visualization.
Moved from evaluation to implementation as we transitioned to the next phase of the project. Joseph
continued RAM benchmarking and testing on the Kria Board to further optimize performance. Tyler
presented his research findings to both the team and client, gaining approval to begin coding the
model division that forms the core of our optimized implementation. Conner documented benchmark
results for RAM and on-chip memory in the main repository, complete with code used to generate and
graph these findings, and has begun more focused testing on ONNX model -> x-model inference for our
U-Net model. Aidan scheduled a one-on-one meeting with an advisor, continuing his research on
cv::mat implementation within the codebase while developing a better understanding of board
operations.
Semester 2
Review of project goals and requirements with the client, revisiting team roles and duties. Reworked
the Gantt chart and planned tasks into smaller increments. Summer accomplishments included Kria board
image testing, ML repo review, git repository cleanup, and matrix algorithm revisions.
Met with client and faculty advisor to re-align on progress and future steps. Joseph created a data
management slide deck, Tyler shared the split model, Conner presented project management improvements,
and Aidan refined the matrix evaluation script for CVmat image format.
Significant progress on model optimization. Conner implemented multiple splitting techniques with
reproducible Docker execution and deployed versions to the board. Tyler conducted initial split model
testing (later analysis revealed Vitis AI compiler scaling issues). Aidan completed C++ code for
multi-threaded model confirmation. Joseph helped get segments running on the board.
Relocated Kria Board to Senior Design lab for easier access. Successfully compiled and verified
optimized models on the board. Conner documented the full generation process for creating optimized
split segments of the U-Net algorithm. Team debugged UNET algorithm segments and reorganized the git
repository structure.
Joseph created a Blink Detection script and helped plan the design poster. Conner improved training
script performance by over 10x and planned the live demo. Tyler worked on documentation handoff for
future teams. Aidan created an eye tracking accuracy script and contributed to split U-Net model
analysis preparation.
Completed performance analysis comparing split vs single UNET model inference. Initial results were
measured without evaluating outputs; upon validation, we discovered the Vitis AI model compiler
incorrectly scaled the last two split segments by a factor of two, requiring input tensor rescaling
for correct output. Corrected results: Single Model (534.65 ms, 1.87 FPS, 42.99 MB) is 9.20x faster
than Split Model with 4 segments (4918.27 ms, 0.20 FPS, 134.00 MB). Team finalized design document
changes, transferred data from the Kria board for future teams, and began planning the final
presentation and live xfce demo.
Design Documents
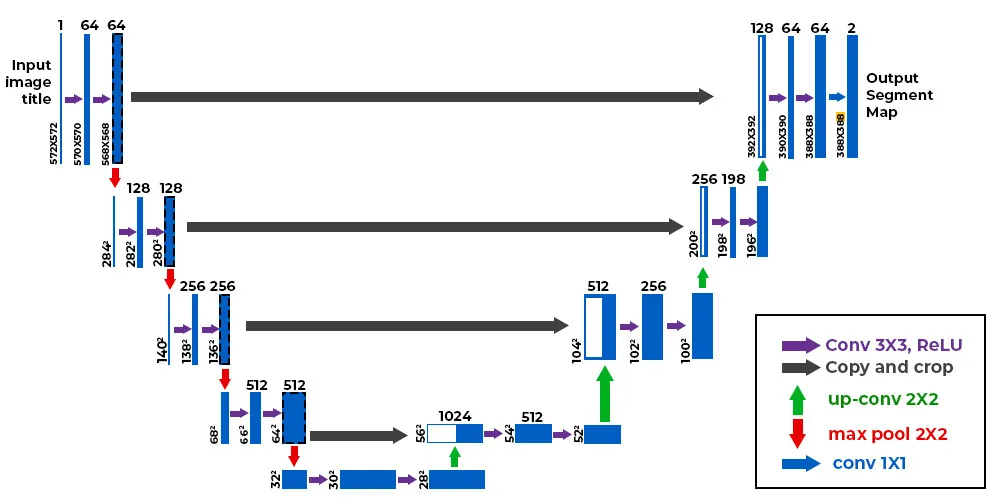
This document outlines the design specifications for our eye tracking semantic segmentation
optimization project. It includes the mathematical approach to dividing the U-Net algorithm,
performance analysis findings (Single Model 9.20x faster than Split Model due to Vitis AI compiler
scaling issues), memory allocation strategies, and hardware configurations for the
AMD Kria KV260
development board platform.
Complete design document detailing the project architecture, implementation, and research findings for the semantic segmentation optimization project.
Visual summary of our project showcasing the research findings, performance analysis, and key
contributions to semantic segmentation optimization for eye tracking on the AMD Kria KV260 platform.
Final presentation slides summarizing the project objectives, research methodology, performance analysis results, and key findings from our semantic segmentation optimization work.